
Moondream 3 Preview
We're excited to announce a preview release of Moondream 3. It's a new architecture of 9B MoE, with 2B active params. Moondream now achieves frontier-level visual reasoning while still retaining blazingly fast and efficient inference.
Why A New Architecture
The impact of AI today has largely been relegated to the digital realm. We have agents that can code, produce digital art, and so on - but very few cases of AI operating in our physical world. No robots to clean our houses, or act as receptionists, or inspect buildings, etc… For Moondream 3, we focused on 4 key areas.
Visual reasoning: despite our focus on smaller models, we don't want that to come at the cost of capability. We want Moondream to be the most capable VLM at real-world tasks.
Trainable: Many vision tasks require specialization. It's not enough for VLMs to be as good as humans. Even humans need training when it comes to complex tasks. Accurately interpreting an X-Ray image, or detecting struggling people in crowds. Moondream must be easily trainable.
Fast: Vision AI applications often need near-realtime performance. Sorting produce, or detecting missing herd animals from a drone, or recognizing security incidents - none of these tasks can be built without fast vision inference.
Inexpensive: Vision AI apps often deal with huge quantities of images, and cost can often be a blocker to adoption. Moondream must be cheap to run at scale.
Moondream 3 achieves these goals by adopting a 9B MoE model, yet still with 2B active parameters. This enables it to achieve, and in some cases beat, frontier-level models, yet still only require 2B active parameters (keeping it fast and inexpensive). We also improved its training dynamics, making Moondream 3 more efficient at learning, especially when using Reinforcement Learning (more on that in subsequent announcements). For more details on the architecture, head to the "Tech Notes" below. One final detail however: we grew the context length from 2k to 32k, making Moondream much better at understanding and producing more complex queries and answers.
Moondream 3 in action
Here are some examples of Moondream 3.
Object Detection
Moondream 3 is astonishingly good at object detection. It goes beyond simple labels (.e.g., "car") and can understand more complex queries. We show results compared to frontier models alongside. These models don't support grounding skills like object detection and pointing natively, so we used a templated query for those (see footer).
Example 1
Prompt: "Runner with purple socks"
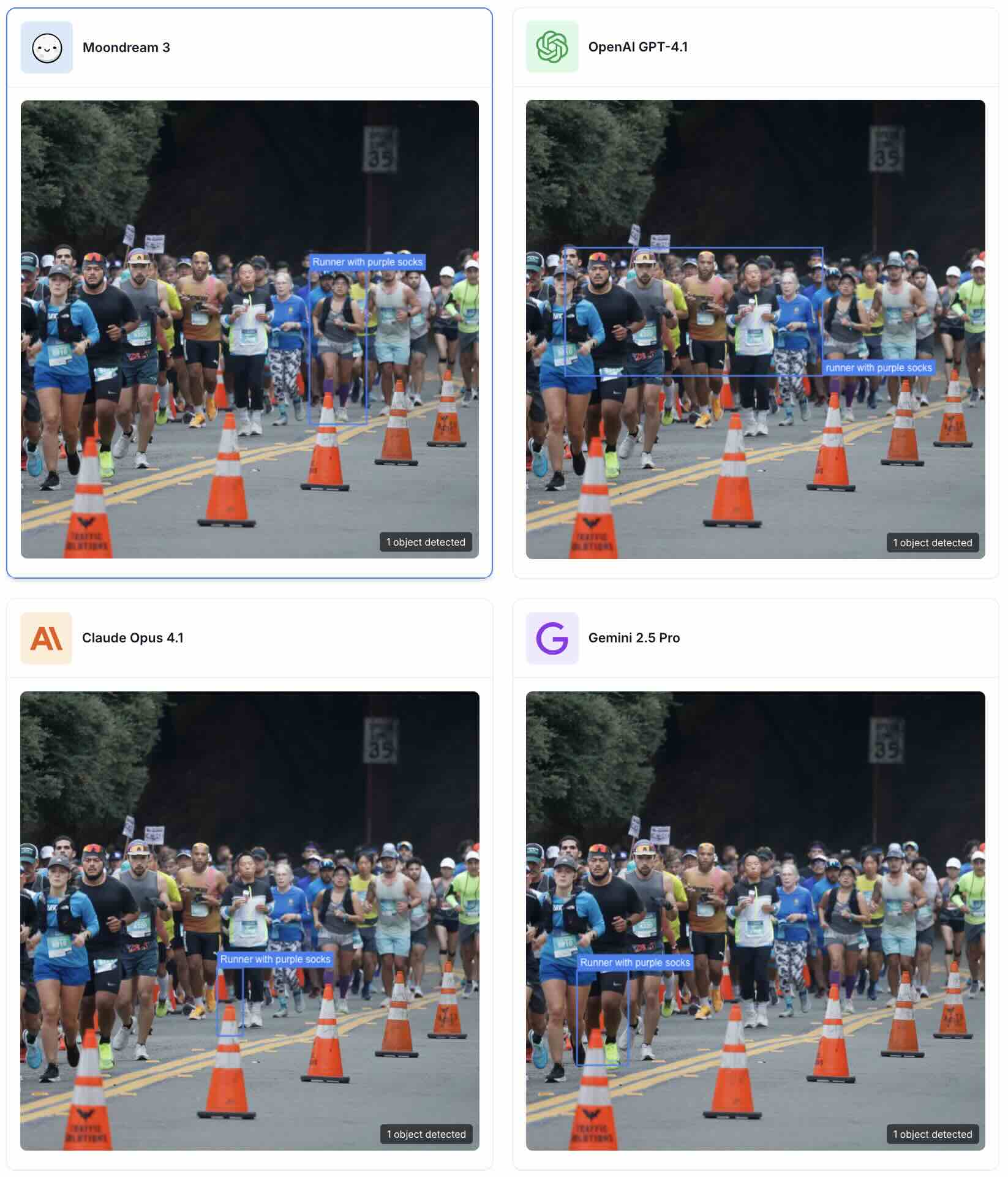
Example 2
Prompt: "Quantity input"
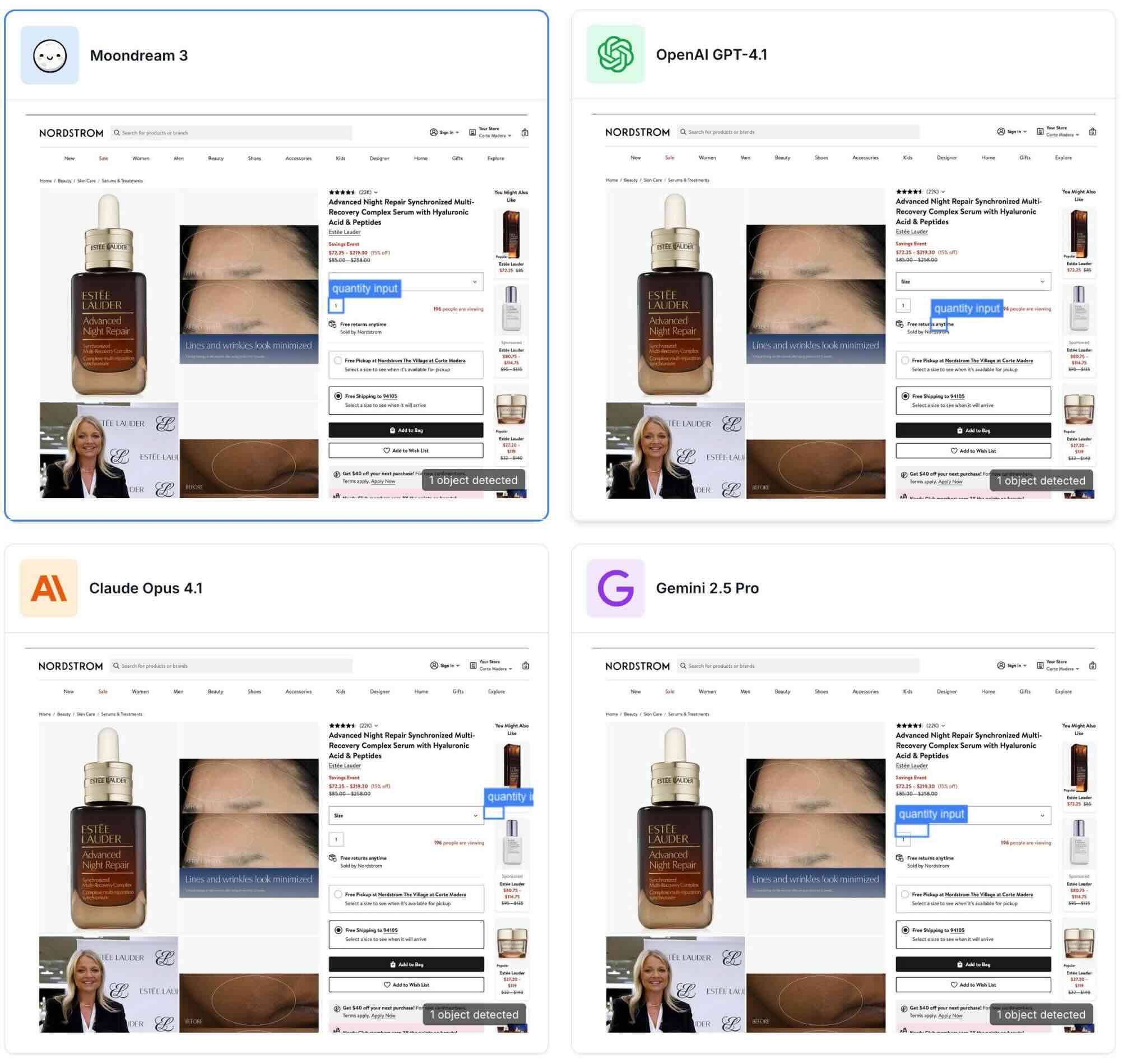
Pointing
Moondream supports pointing as a native skill.
Example 3
Prompt: "Bottle"
![]()
Example 4
Prompt: "Best utensil for pasta"
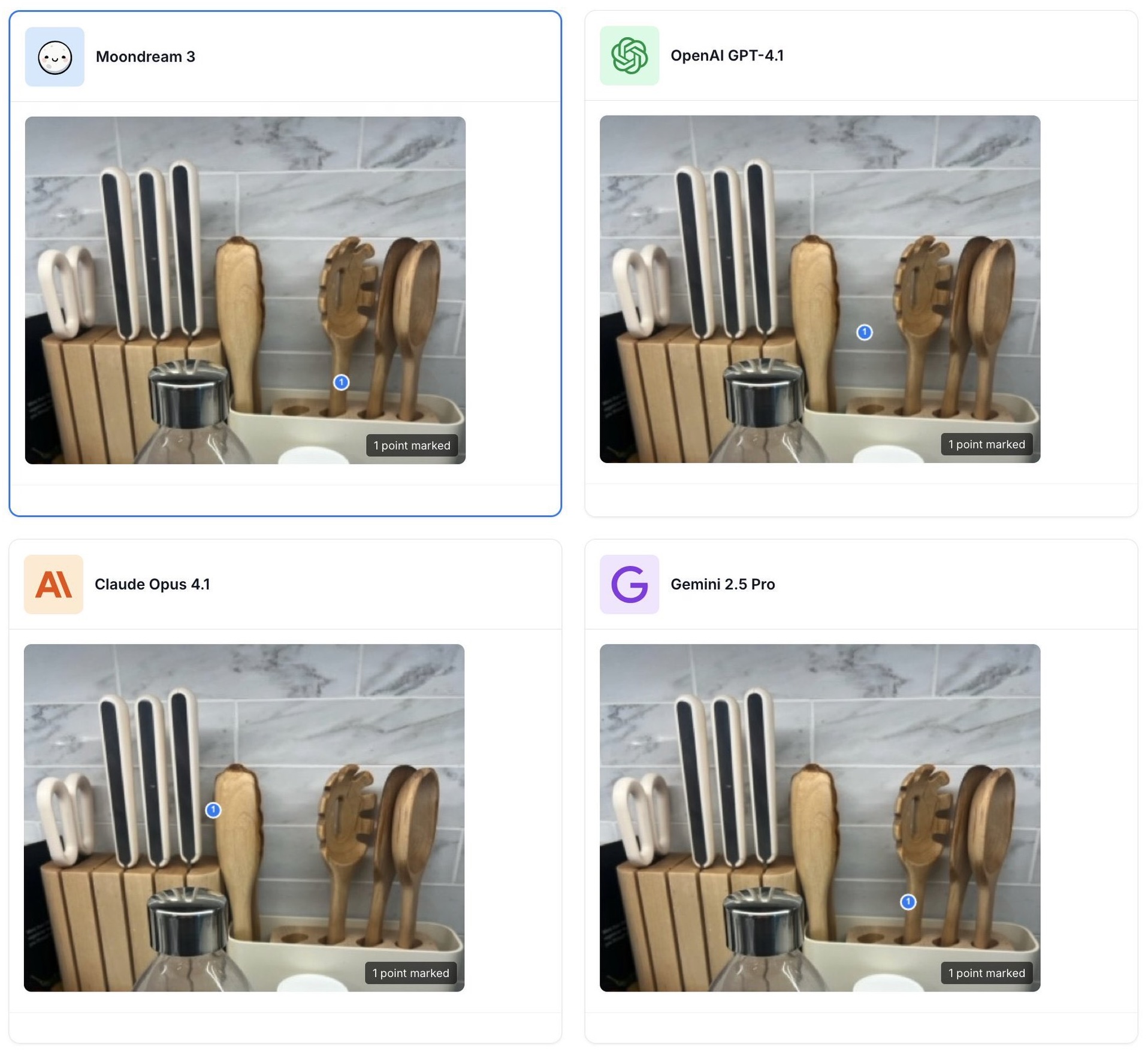
Structured output
With a longer context length, Moondream 3 generates intelligent structured outputs with minimal prompting.
Example 5: Sled dogs
 Prompt
Prompt
"A JSON array with keys: dog_id, fur_color, harness_color."
Result
[
{ "dog_id": 1, "fur_color": "light brown", "harness_color": "red" },
{ "dog_id": 2, "fur_color": "dark brown", "harness_color": "red" },
{ "dog_id": 3, "fur_color": "gray", "harness_color": "red" },
{ "dog_id": 4, "fur_color": "white", "harness_color": "red" },
{ "dog_id": 5, "fur_color": "dark brown", "harness_color": "green" },
{ "dog_id": 6, "fur_color": "light brown", "harness_color": "green" },
{ "dog_id": 7, "fur_color": "dark brown", "harness_color": "black" },
{ "dog_id": 8, "fur_color": "white", "harness_color": "black" }
]
OCR
Moondream 3 has drastically improved its OCR abilities. Our vision encoder can get tripped up on tiny fonts (working on it), but it's now useful in many real-world cases.
Example 6
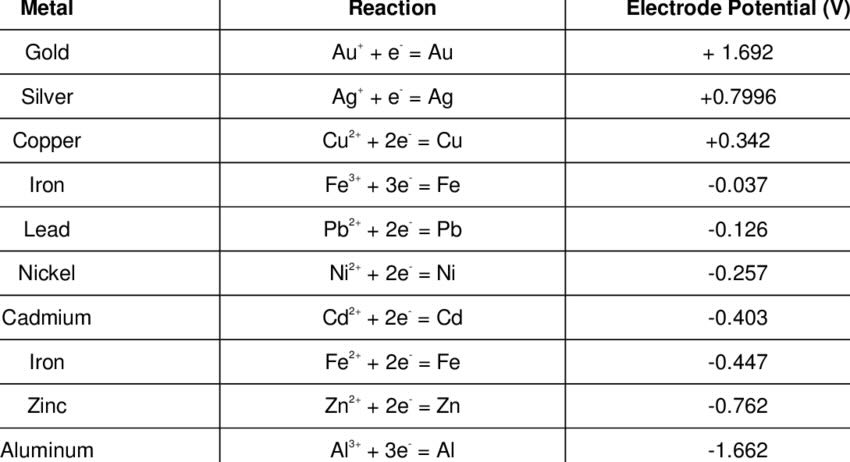 Prompt
Prompt
"Convert to markdown""
Result
| Metal | Reaction | Electrode Potential (V) |
|---|---|---|
| Gold | Au⁺ + e⁻ = Au | +1.692 |
| Silver | Ag⁺ + e⁻ = Ag | +0.7996 |
| Copper | Cu²⁺ + 2e⁻ = Cu | +0.342 |
| Iron | Fe³⁺ + 3e⁻ = Fe | -0.037 |
| Lead | Pb²⁺ + 2e⁻ = Pb | -0.126 |
| Nickel | Ni²⁺ + 2e⁻ = Ni | -0.257 |
| Cadmium | Cd²⁺ + 2e⁻ = Cd | -0.403 |
| Iron | Fe²⁺ + 2e⁻ = Fe | -0.447 |
| Zinc | Zn²⁺ + 2e⁻ = Zn | -0.762 |
| Aluminum | Al³⁺ + 3e⁻ = Al | -1.662 |
Benchmarks
Here are some early benchmark results. We show it alongside some top frontier models for comparison. In practice, however, it's probably not a fair comparison for Moondream since, in practical terms, Moondream produces answers in fraction of the time of these bigger models. We'll publish more complete results later and include inference times to make this clearer.
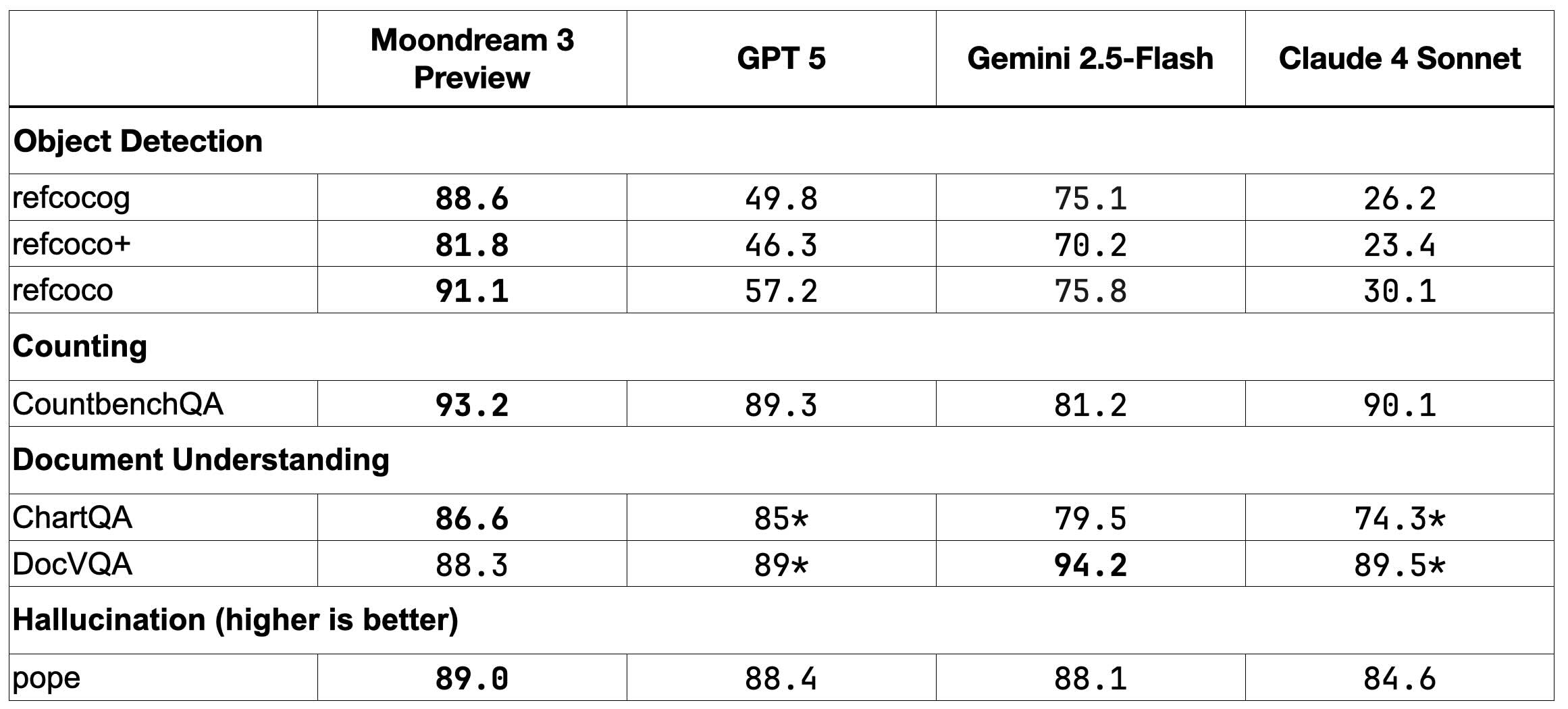
- Scores with a "*" next to them indicate that we used a 100 random question sample rather than evaluate the whole benchmark.
MD3 Preview Technical Notes
Here are some details on our new model architecture. Moondeam 3 is a fine-grained sparse mixture-of-experts model with 64 experts, of which 8 are activated for each token. We initialized it from Moondream 2 (a 2B dense model) using drop upcycling. We also extended the usable context length to 32K tokens, which is critical for few-shot prompting and agentic workflows with tool-use. We don’t fully leverage this longer context in our post-training yet (part of why it's only a preview release). The full 32k context is available for you if you're interested in fine-tuning the model.
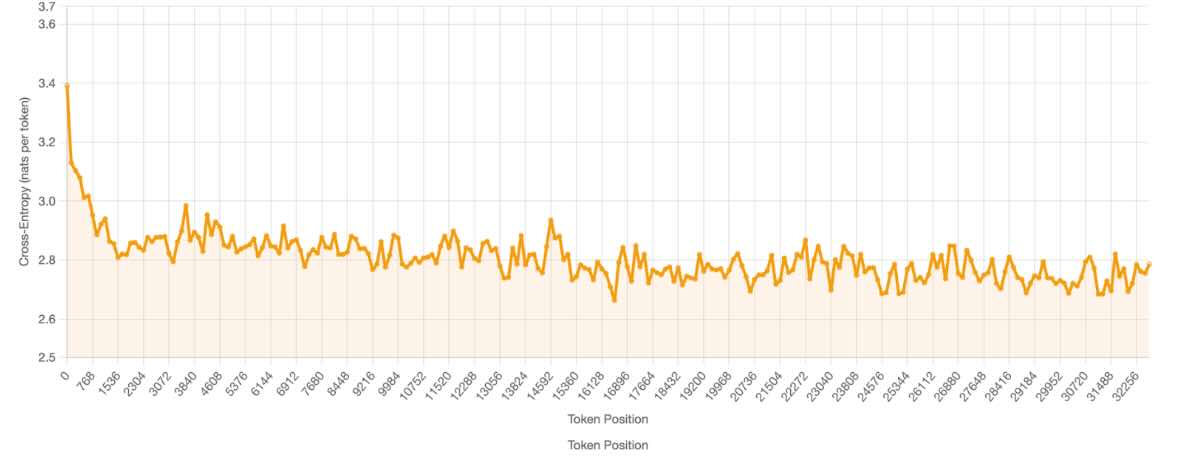
 (Figure: Long-context perplexity evaluation on GovReport dataset. Each point shows the average cross-entropy loss (nats per token) for a 128-token sliding window at that position, measured across 100 documents truncated to 32,768 tokens.)
(Figure: Long-context perplexity evaluation on GovReport dataset. Each point shows the average cross-entropy loss (nats per token) for a 128-token sliding window at that position, measured across 100 documents truncated to 32,768 tokens.)
We do not use a separate context-length extension phase during training, instead opting to interleave long-context samples while pretraining with a default context length of 4096 tokens. Many context length extension methods like YaRN include an attention temperature scaling component. Inspired by this, we adjust the architecture to enable learned temperature scaling as a function of position, and find this helps with long context modeling.
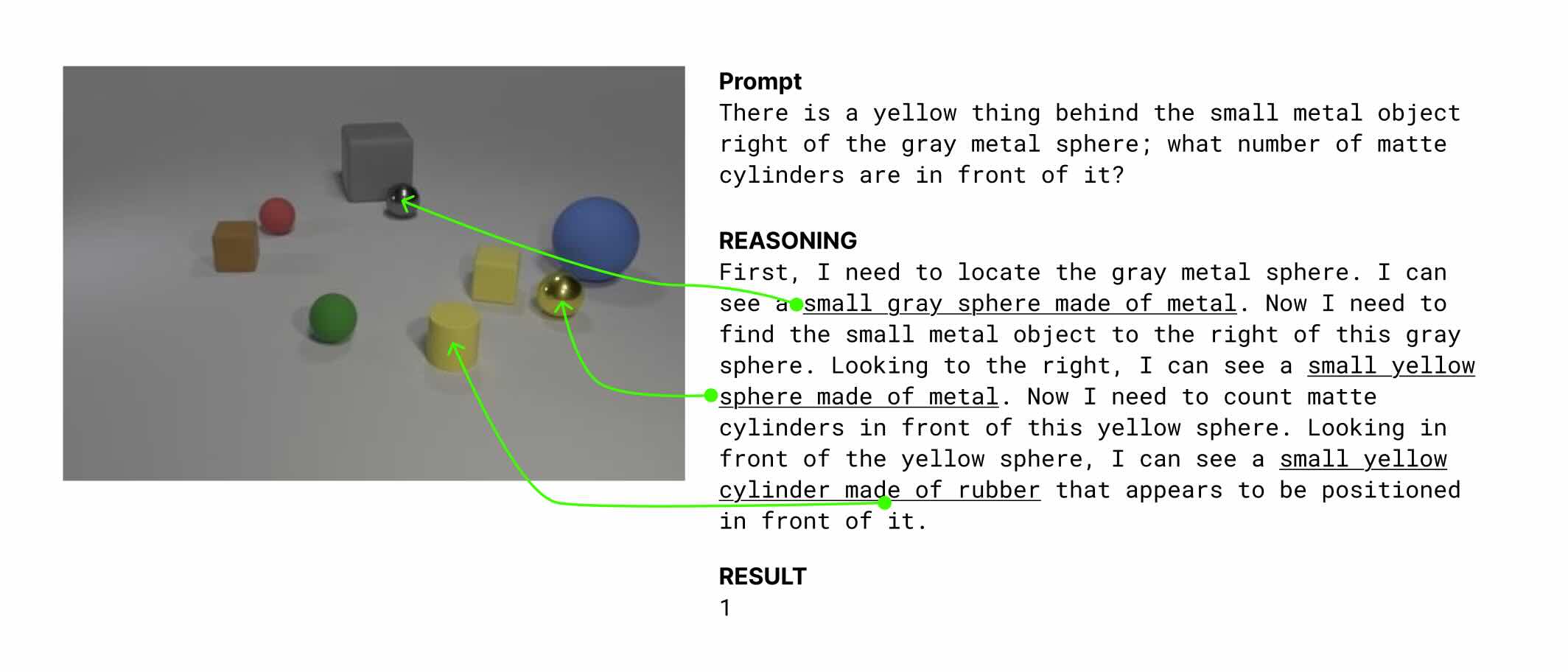
Like our last 2B release, this is a hybrid reasoning model that supports both reasoning and non-reasoning mode. Unlike other reasoning models, however, Moondream focuses on visual reasoning with grounding. Here’s an example of what that means:
Each chunk of underlined text in the reasoning is grounded, meaning the model references a particular part of the image. In our playground, you can see what the model is focusing on by hovering over the text.
 The model starts with only a small set of visual-reasoning examples, and gradually learns to rely on them more during our reinforcement learning (RL) post-training phase. RL proved so effective that, as we refined our training approach, post-training ended up using more compute than the initial pre-training itself.
The model starts with only a small set of visual-reasoning examples, and gradually learns to rely on them more during our reinforcement learning (RL) post-training phase. RL proved so effective that, as we refined our training approach, post-training ended up using more compute than the initial pre-training itself.
It was trained with load-balancing and router orthogonality losses to help similar tokens specialize together early on, then had load balancing disabled in post-training to avoid catastrophic forgetting from distribution shift. Finally, attention tweaks like learnable temperature and LSE suppression sharpened focus and cut noise—boosting accuracy and clarity.
Conclusion
This preview release comes with some caveats. We haven't optimized the inference code yet, so inferences are much slower than anticipated (we're working on it!). We're also still actively training this model, and we expect the capabilities and benchmarks scores to improve. We also plan to produce variants of this model (e.g., quantized versions and distilled smaller versions).
The model is now available on the Moondream playground, and you can download it on HuggingFace (Moondream Station will be updated soon). Hit us up on our Discord if you have any questions.
(1) Frontier models don't support object detection natively, so this prompt was used instead:
Detect these objects in the image: [comma-separated list].