
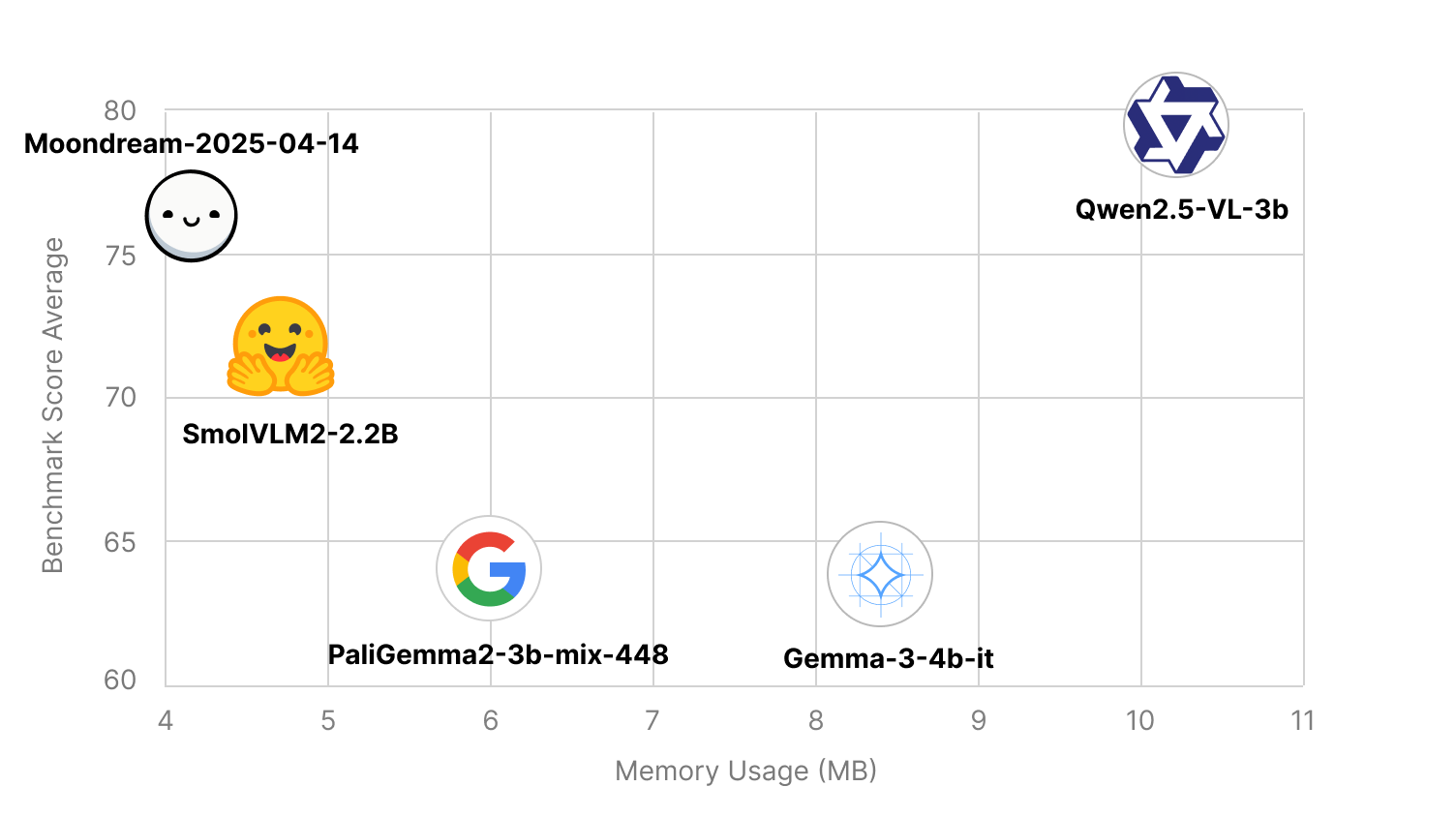
Moondream is not just one of the tiniest VLMs. It's the world's most efficient VLM. It produces highly accurate answers with the least computing possible. On a graph with intelligence on the Y axis and resource usage on the X axis, Moondream aims to be top left.
AI is still early in its development, and just as we've seen mainstream computing evolve from mainframes to desktops, mobile, and even smaller devices, so will AI. This is especially true for Vision AI. Almost every physical device is improved if it can reason about its surroundings. Today this often means streaming video or images back to the cloud, which is slow, costly, and privacy-problematic. But with improving hardware and models, this is about to change, and today is another solid step forward.
But efficiency isn't just for the edge, it's for the cloud too. Analyzing vision at scale can be costly. Customers turn to Moondream when scale becomes a concern. Analyzing millions of images, or thousands of hours of video with Moondream is more cost effective than with any other VLM.
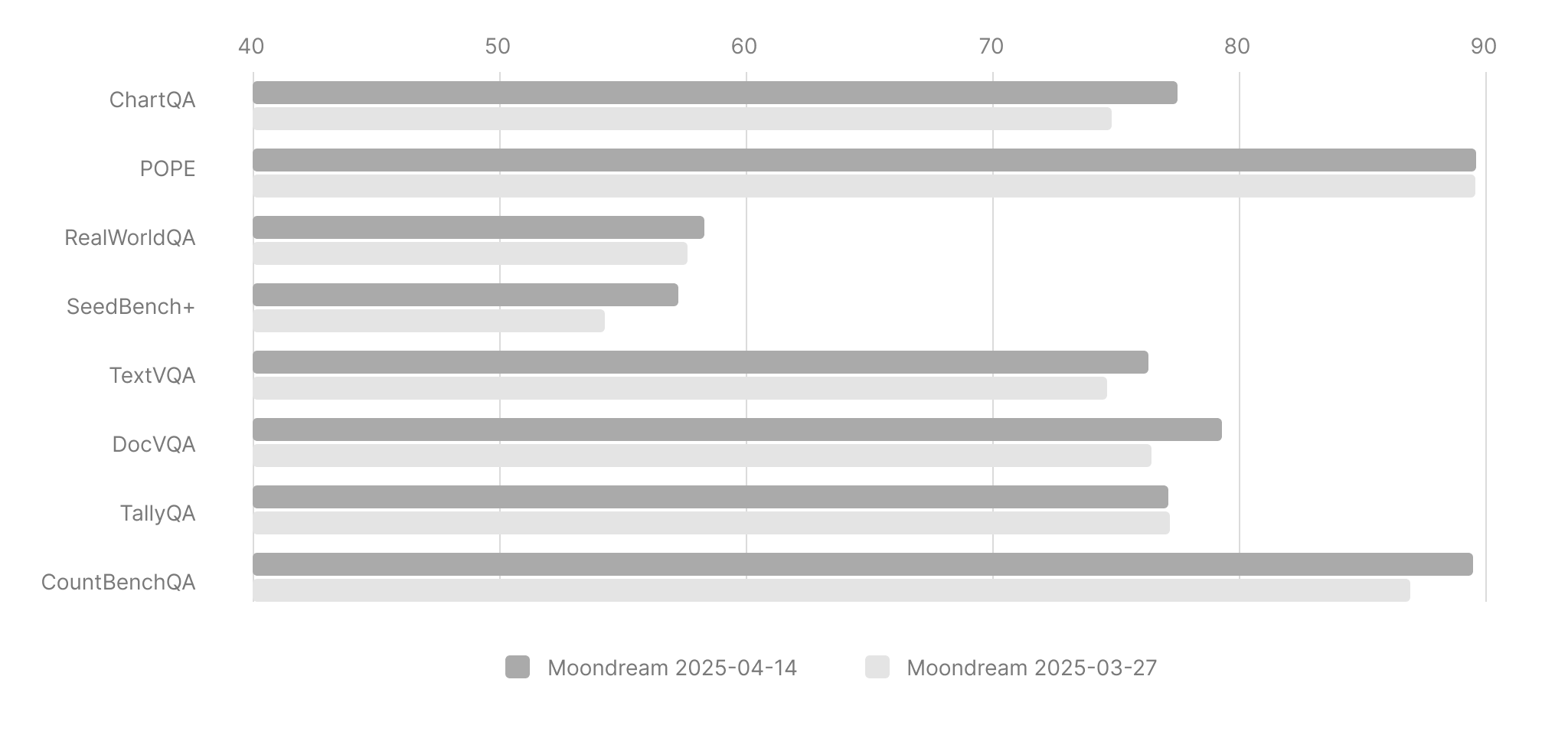
That's why we're excited to announce Moondream 2025-04-14. As usual, we've improved on all of the benchmarks we focus on, with some notably large improvements. Let's first look at how it stacks up vs our previous release just a few weeks ago:
Now let's see where that puts us vs other top open source small VLMs.
Tech Notes
This release of Moondream was trained on about 450B tokens. For contrast, models like Gemma 3 4B have been trained on 4 trillion tokens, and Qwen 2.5 VL utilized 18 trillion tokens for text modeling, plus an additional 4 trillion tokens for their VLM. Our efficiency in producing a high performance model with a fraction of the training budget is the result of:
- High-Quality Data: We've observed that small models are especially sensitive to noisy data. We produce training data that contains both rigorously filtered real-world data and carefully crafted synthetic data, designed to minimize domain gaps.
- Focused Scope: Moondream is specifically designed for developers creating computer vision applications. We prioritize relevant capabilities over broader use-cases like multi-turn conversations or haiku writing.
- Training Techniques: We've developed a set of training methods that maximize training efficiency. We keep most of them proprietary, but here are two we're disclosing today:
- We use a custom second-order optimizer, crucial for balancing conflicting gradients, such as object detection versus text generation tasks.
- We use a self-supervised auxiliary image loss that significantly accelerates model convergence.
Our focus this release was to improve on our previous one by targeting document understanding, charts, and user interfaces. Moondream has become quite proficient at reading documents. Here are examples of document and layout understanding:


This improvement in document and text reading has also yielded sizeable bumps in our text-related benchmarks:
- ChartQA: Improved from 74.8 → 77.5 (82.2 with PoT)
- DocVQA: Improved from 76.5 → 79.3
- TextVQA: Improved from 74.6 → 76.3
Performance
Counting
This release of Moondream has seriously counting chops (e.g. "how many birds in this image"). To see how good we got, here's a chart comparing ourselves to all the big names in VLMs.
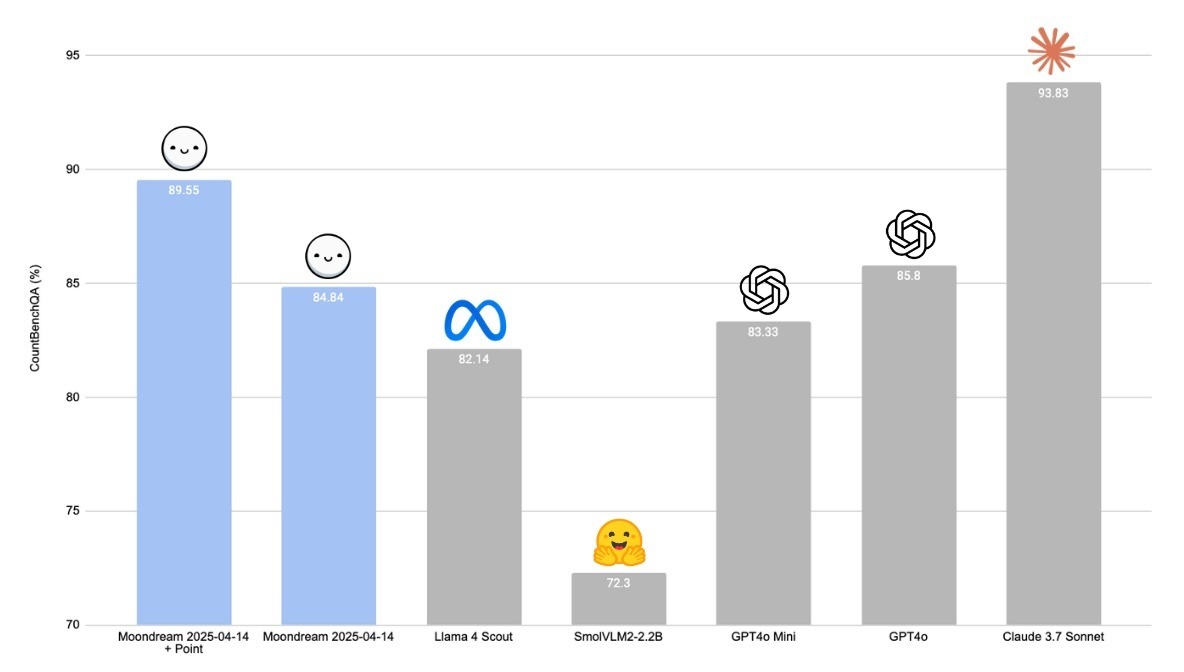
Chart Understanding
Chart understanding has been a key focus for this release. Charts require models to ground text and numbers in a visual layout, then reason over them precisely. On ChartQA, Moondream improves from 74.8 in our last release to 77.5, and 82.2 with Program of Thought (PoT) prompting.
PoT is a prompting strategy where the model generates and executes code to solve problems step-by-step. This is especially valuable in chart QA, where reasoning failures often stem not from misreading the chart, but from making small but critical logical errors — like summing three correct numbers incorrectly. Rather than expecting the model to always reason flawlessly in natural language, we let it write and run code.

Here's a few more notes from this update:
- To access the OCR capability for docs and tables, use the prompt "Transcribe the text" or "Transcribe the text in natural reading order".
- Object detection supports document layout detection (figure, formula, text, etc).
- UI understanding has improved, with ScreenSpot F1@0.5 up from 53.3 to 60.3.
Conclusion
As excited as we are for this launch, we have a lot more coming up for next releases too. Here's a few areas we're focused on:
- Repetition Handling: We've seen an increase in repetitions in our inferences, especially when generating long document answers. We've added temperature and nucleus sampling to reduce output repetition, with a repetition penalty setting coming soon. Training adjustments will further mitigate this issue in future releases.
- Tokenizer Upgrade: Our current tokenizer, derived from the three-year-old CodeGen model, hinders optimal training and inference performance. We plan to adopt either a traditional BPE tokenizer (ensuring broad ecosystem compatibility) or a BPE variant (optimized for efficiency).
- Bounding Box Accuracy: Currently, the model occasionally generates bounding boxes encompassing multiple items. We have identified the root cause and a solution is forthcoming. Meanwhile, prefixing object detection queries with "(coco)" can help mitigate this issue.
- Continued Training: As performance continues to steadily improve, we anticipate training for an additional 200 billion tokens before the next release.
We invite you to go check it out for yourself in our playground, or start coding today.
You can run it locally using our new Moondream Server (Mac and Linux for now, Windows coming…), or in our cloud (with a generous free tier).
Happy Moondreamin'.