
Building smarter vision apps means teaching machines to think about images instead of just labeling them. Our newest Moondream release does exactly that. It reasons more accurately, spots objects more sharply, and the twist is that it writes answers up to 40 % faster. Let’s walk through what changed, and why it matters.
Grounded Reasoning
Simple tasks—like reading a date off a receipt need little thought. Harder ones, like finding the median value on a chart, demand real reasoning about where things are and how they relate.
Moondream now supports grounded reasoning, allowing the model to spend some time to think about the problem and reason precisely about positions and spatial relationships within images before generating an answer. This unlocks performance gains for tasks that depend on accurate visual interpretation.
Moondream can now pause, look around the picture, and think step-by-step before answering. We call this grounded reasoning because the model can reason, using both logic and visual facts about the image to produce more accurate answers.
Take chart understanding, for example. Without reasoning, Moondream does its best by essentially guessing ths answer in one shot. With reasoning on, it breaks the job into three small steps, then nails the answer.
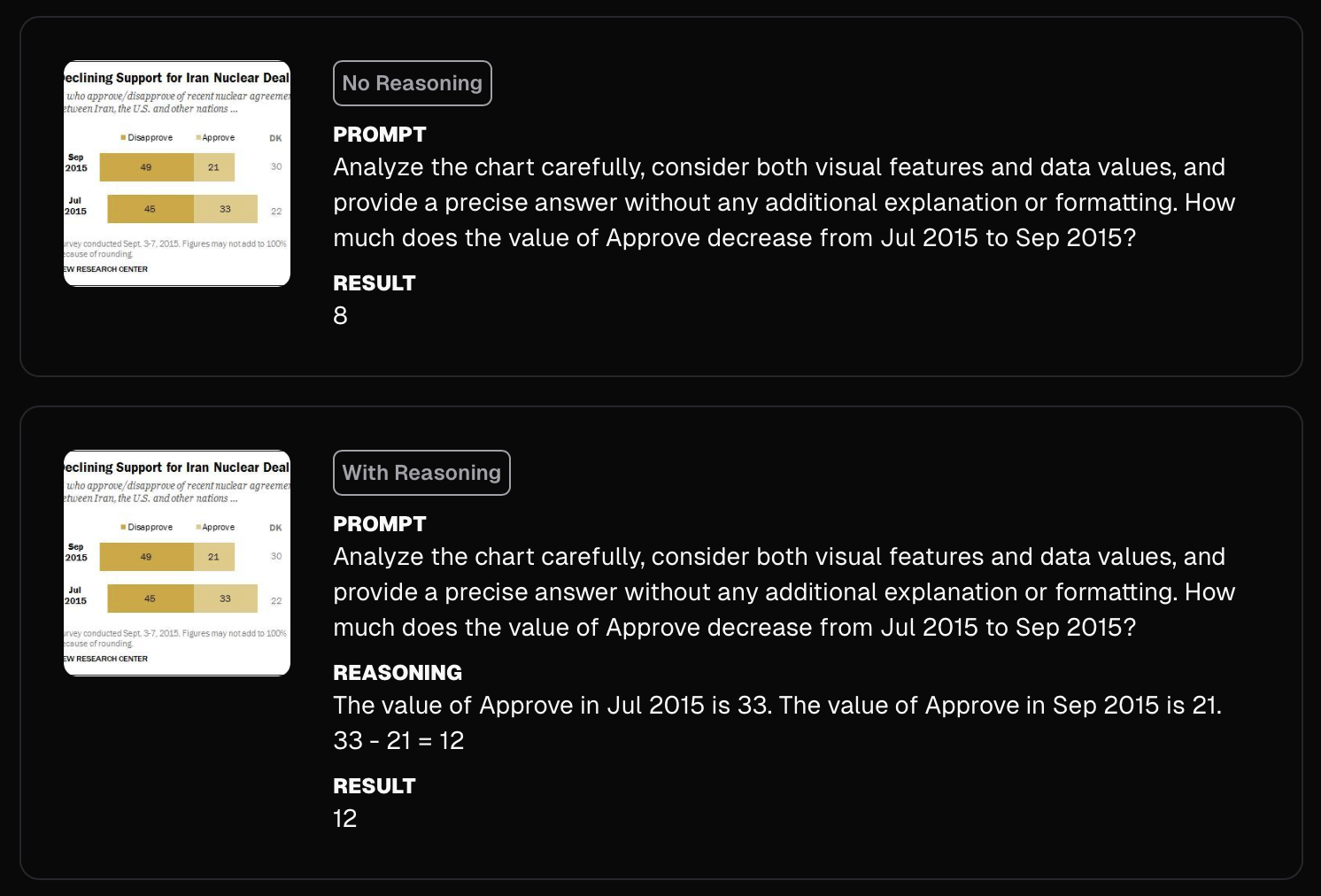
Moondream's reasoning is specifically designed for accurate visual reasoning. The model can choose the "ground" its reasoning with spatial positions in the image when needed to accurately solve a task. Consider counting objects in images, for example. When there are more than a couple of instances of an object in an image the model chooses to explicitly point at them in the reasoning trace, similar to how a human may tackle the same problem.
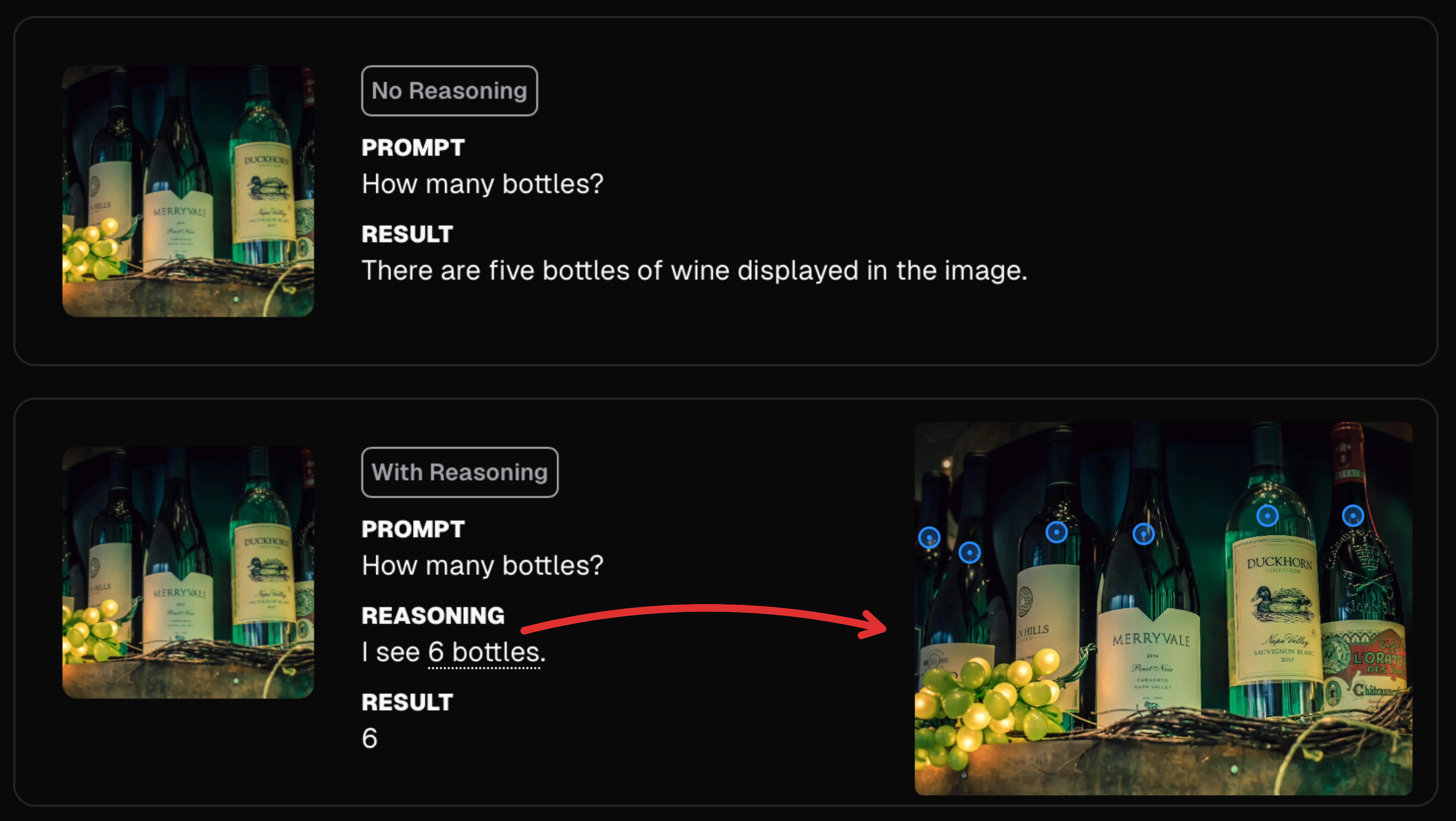
The recent Vision Language Models are Biased paper shows that many VLMs suffer from confirmation bias when counting, returning memorized knowledge instead of actually counting when they see familiar objects. As we deploy VLMs in high-stake applications, it's critical that we are able to ensure and audit that the models are actually reasoning about the image instead of simply performing sophisticated pattern matching. Our approach to visual reasoning not only helps the model reason about images, but also provides a way for users to audit what it's doing and understand failure modes.

Moondream supports both reasoning and normal queries with the same model, meaning you can trade off accuracy vs speed depending on the complexity of the task you're trying to performance. You can enable reasoning by passing reasoning=True with the query skill. This reasoning mode is powerful but still experimental. For simpler tasks, the original mode may perform better, so we recommend trying both.
How We Taught It to Think
We've started using reinforcement learning (RL) to train Moondream. If you're not familiar with RL, here's a short description of how it works. Traditionally, models are trained by asking them questions where the correct answer is known (aka "Ground Truth"). If the model doesn't answer correctly, we apply a corrective change in the model weights to encourage it to answer better next time. This process is called "supervised learning".
RL works a little differently. We start the same way, with a question where we know the correct answer. With RL, however, we ask Moondream to generate numerous answers using different temperatures, then we grade the answers on good they are. Not only if the answer is correct, but whether it used correct reasoning. This is easier done with tasks that have singular answers (e.g., "What's the sum of the numbers the table?"). For more open-ended answers (e.g., "Caption this image"), we use another Moondream model to judge the answer.
So far we've used RL to train Moondream on 55 tasks and the results are impressive. We plan to increase this to ~120 before the next update to the model.
With smaller models such as Moondream, it's common practice to "bootstrap" the model with reasoning traces from a bigger model. We haven't taken this approach for two reasons: first, our context length is currently limited to 2048 tokens, and this will need to be increased before we can train on longer reasoning traces. Secondly, most open reasoning models are focused on mathematical and coding reasoning, and this is not as effective for visual reasoning.
Sharper Object Detection
Moondream's Object Detection skill just got a lot better with this release. Previously, Moondream had a tendency to clump together objects that were close to each other, and sometimes struggled with finer-grained object specifications (e.g. "blue bottle" instead of just "bottle"), compared to Moondream's pointing capability.
This was largely due to the quality of the the datasets we used. Object detection datasets generated by humans tend to be messy and imprecise as drawing highly accurate bounding boxes is tedious. Annotators often take shorcuts, and sometimes draw a single box around multiple instances when they're close to each other in the image.
We used RL to overcome this, and the results are impressive. We'll be sharing more details about this in a separate blog post, but for now, here's a sample of the results.

Faster Text Generation
Moondream now generates answers 20-40% faster than before. This is because we upgraded the model to use a "superword" tokenizer that encodes text more efficiently. This means Moondream needs to emit fewer tokens to generate the same answer, and we achieve this without any drop in accuracy.
Changing a tokenizer typically involves a costly step to retrain the entire model. We built a lightweight "tokenizer transfer hypernetwork" that enabled us to adapt smoothly to new tokenizers without retraining.
Lastly, this "tokenizer transfer hypernetwork" also makes it easier to train multilingual variants in the future.
UI Understanding
Moondream's performance on ScreenSpot, a benchmark for UI understanding, jumped significantly from 60.3 to 80.4. This makes Moondream a great choice for UI-focused applications that require fast element localization.
While the model cannot be used as a standalone computer use agent yet, it can work very effectively when treated as a tool to be used by a larger agentic model. This is the setup used by projects like Magnitude, where a bigger LLM writes test cases that leverage Moondream for UI understanding tasks. This separation of planning and execution models allows them to run tests more quickly and reliably than using alternatives like OpenAI or Anthropic's Computer Use APIs.
Looking Ahead
Grounded reasoning, smarter object detection, faster tokenizer, and better UI understanding represent a big step forward for Moondream. These fundamental advances also open the door to more improvements on the horizon. We look forward to pushing the model to achieve deeper reasoning capabilities and broader task coverage, and even more speed optimizations.
There's more to this release than what we've covered here, so check it out yourself. Checkout our free online playground, or our free cloud API, or run it locally using Moondream Station - also free.. If you prefer really low-level stuff, you can use it directly using Hugging Face Transformers.
Happy Moondreamin’!