
When we compare model sizes, we usually quote the number of parameters. But that doesn't tell the whole story. Depending on other factors, a model with fewer parameters may actually use more memory, and run inference slower than a larger model. That's why we prefer to focus on actual memory size and inference speed.
Today we're excited to announce a new feature that makes Moondream run faster and use less memory: 4-bit quantization. In case you're not familiar, quantization is a technique that reduces the number of bits used to store a model's weights. For example, weights are usually stored as 16-bit float, which take 2 bytes each. A 4-bit weight only takes 0.5 bytes.
The challenge with quantization is that it can lead to a loss of model accuracy. We've been working on this for a while, and we're excited to share that our 4-bit quantized model reaches 99.4% of the accuracy of the full precision model. In practice you'd probably never notice the difference.
Meanwhile you probably would notice the speedup and memory improvement. The peak memory usage is reduced by 42% (from 4.2GB to 2.4GB) and, the inference speed is increased by 34% (on an RTX 3090), although the speedup may vary by machine. On the accuracy front, we measure the average score on 8 popular vision benchmarks. The 4-bit quantized model achieved an average score of 74.5 vs 74.9 for the full precision model.
So let's update our chart from our 2025-04-14 model release.
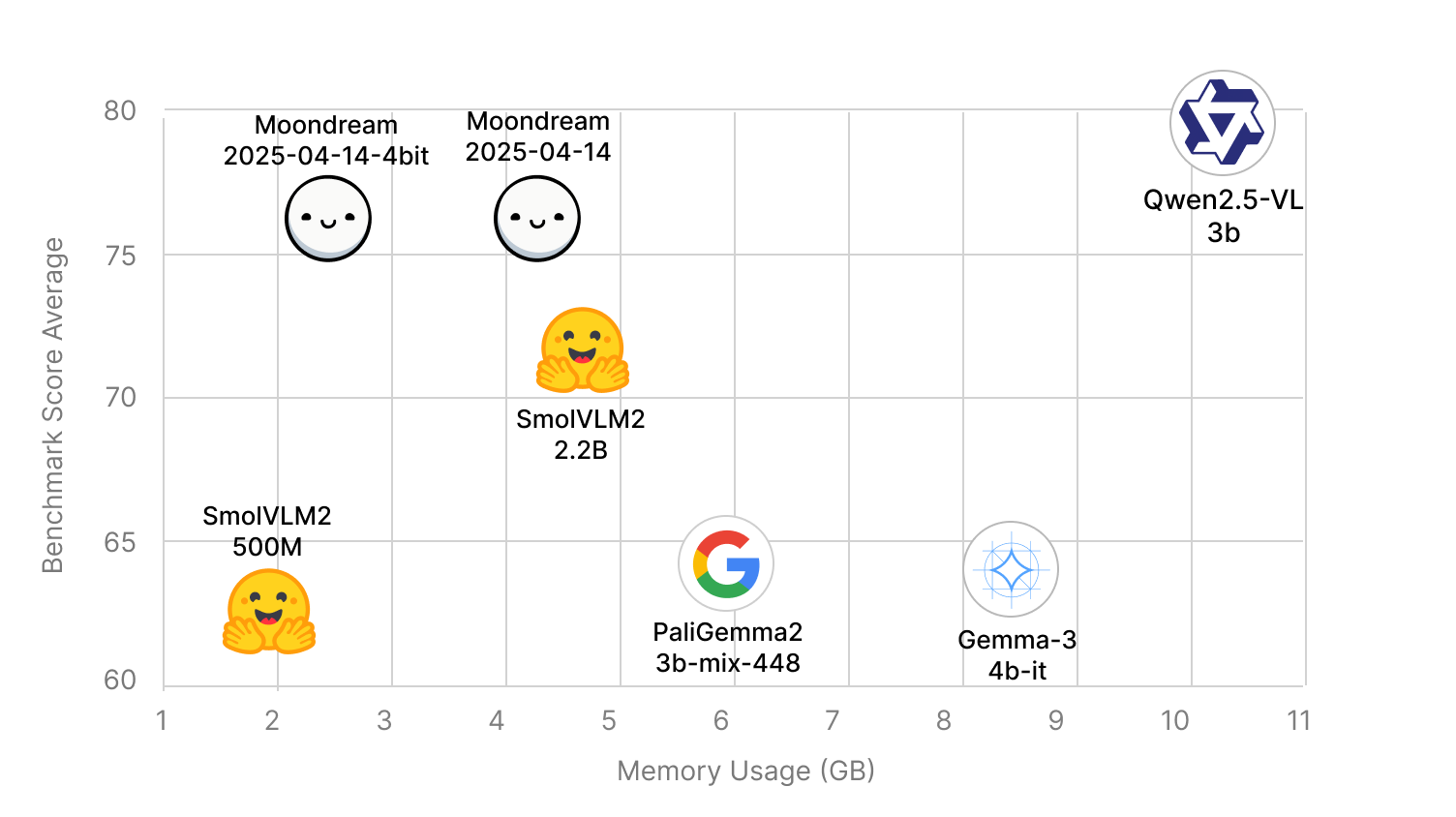
Both the full precision model and the 4-bit quantized model are available as open source. The 4-bit model is currently available for Linux users in Moondream Station (our one-click solution), with Mac support coming soon. Advanced users can also access the model directly via Hugging Face Transformers.
Happy Moondreamin'.