
We're excited to launch Moondream Cloud, a hosted version of Moondream that makes it easy to build cutting-edge vision applications.
When choosing vision AI tech, three things matter most: intelligence, speed, and cost. With our recent launch of Moondream 3 Preview, our model already delivers top-tier intelligence, reaching SOTA on visual reasoning and grounding tasks, outperforming top frontier models. Our Moondream Cloud release focuses on the other two: speed and cost.
Pricing
Moondream Cloud is pay-as-you-go. No subscriptions, no commitments, just load up credits and you're done. To help you start building right away, you get $5 in free monthly credits too (no credit card required!).
Our pricing is token based: Moondream 3 Preview costs $0.30 per million input tokens, and $2.50 per million output tokens. These token rates are simlar to Gemini 2.5 Flash and GPT-5 Mini. But token pricing doesn't tell the full story. Moondream uses a custom SuperBPE tokenizer that means we generate 21% fewer tokens for the same output text. We have dedicated grounding tokens that represent points with two tokens and object bounding boxes with three tokens, where competing models have to use tens of tokens. And we represent images of all resolutions with 729 tokens, leading to significant savings on prefill.
We simulated a workload where each of the three examples below are processed once a minute, for 30 days. To do this for all three images would cost:
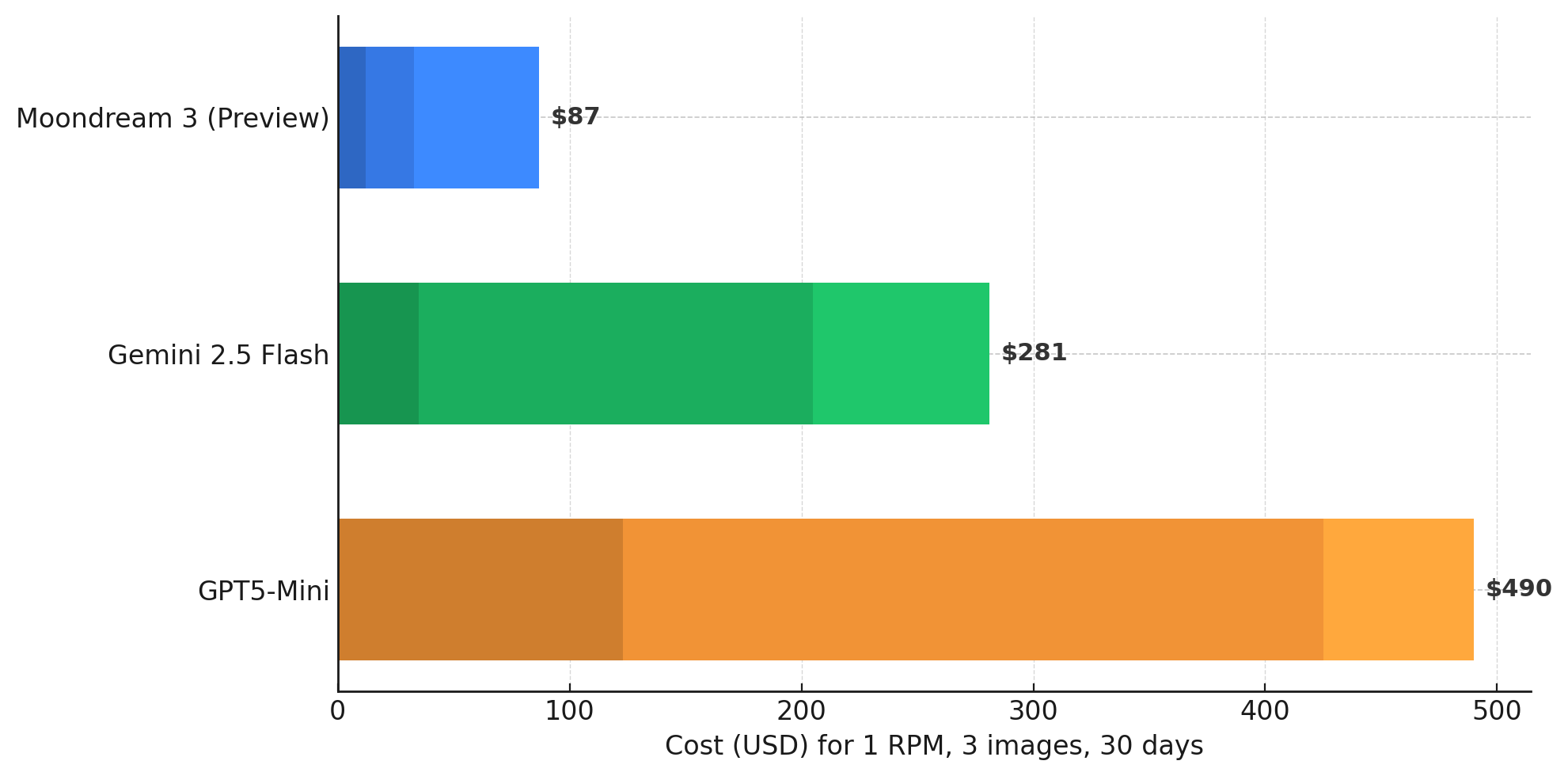
Comparisons
We compared Moondream Cloud with Gemini Flash 2.5 and GPT-5 Mini. Both are vision-capable and similarly priced. (We skipped Claude Haiku 4.5 because its vision capabilities were significantly behind on the tasks we evaluated.)
Example 1: Pointing
| Moondream 3 (Preview) | Gemini 2.5 Flash | GPT-5 Mini | |
 |  |  |  |
| Average runtime | 1.52 seconds | 3.02 seconds | 27.58 seconds |
| Input tokens | 737 | 1,352 | 419 |
| Output tokens | 25 | 241 | 1,372 |
| Monthly cost (1 RPM) | $12 | $35 | $123 |
In this example, Moondream is cheaper because we use both fewer input and fewer output tokens. We require fewer tokens both because we encode the image efficiently (compared to Gemini 2.5 Flash), and because we don't need a complicated text prompt to get the model to output just the list of 2D points. On the outputs, Moondream benefits from having dedicated grounding tokens, requiring only two tokens per point. The result is that Moondream is significantly cheaper to run.
Example 2: Object detection
| Moondream 3 (Preview) | Gemini 2.5 Flash | GPT-5 Mini | |
 |  |  |  |
| Average runtime | 4.56 seconds | 7.69 seconds | 52.88 seconds |
| Input tokens | 737 | 1,839 | 1,849 |
| Output tokens | 103 | 1,524 | 3,271 |
| Monthly cost (1 RPM) | $21 | $170 | $302 |
Again, Moondream is more efficient because our grounding tokens mean we only emit three tokens per bounding box -- two tokens encoding the position of the middle of the box, and one token encoding both the height and width. Like before you'll notice we're also significantly more accurate.
Example 3: OCR
 |
|
This one is more evenly matched, since we're emitting normal text output. But Moondream still wins on cost because of more efficient image encoding, and more efficient output tokenization (using our custom tokenizer).
Throughput and Data Privacy
On the free tier, we allow up to two requests per second. When you hold $10 or more in paid credits, we increase that to 10 requests per second. We never train on your data, and no data is persisted after returning responses.
We also offer enterprise plans with:
- On-prem inference (run Moondream in your own infrastructure)
- Compliance options (e.g. HIPAA)
- Dedicated consulting and support
- Volume-based pricing
Reach out at sales@moondream.ai to discuss your needs.
Conclusion
Moondream exists for one reason: to power the next wave of vision AI agents. Our new 9B parameter mixture-of-experts Moondream 3 (Preview) model combines the speed of a 2B model with state-of-the-art visual reasoning and grounding, with no compromises. And now, with Moondream Cloud, using it as simple as it gets. Fast, cheap, smart -- pick three.
Go to the cloud console to grab an API key, then check out our documentation to get started!